The Schema Markup Hierarchy: Structuring Data to Signal Topic Authority Across Your Content Clusters
Schema markup applied to individual pages without a defined hierarchy connecting them produces zero measurable lift in conversion rates.

The Schema Markup Hierarchy: Structuring Data to Signal Topic Authority Across Your Content Clusters
Schema markup applied to individual pages without a defined hierarchy connecting them produces zero measurable lift in conversion rates. I've watched marketing teams spend weeks tagging every page on their site with Article schema, validating each one in Google's Rich Results Test, and then wondering why their organic conversion rate stayed flat. The problem isn't the markup itself. The problem is treating structured data as a page-level checklist instead of a site-level architecture decision.
When your structured data topic clusters mirror the relationships between your actual content, you give search engines and AI systems a machine-readable map of your expertise. That map changes which queries surface your pages, how those pages appear in results, and whether the traffic they attract has any intent to convert. Disconnected schema on disconnected pages does none of this.
The rest of this article defends that claim with three pieces of evidence from real implementation data, and explains exactly how to build a schema markup strategy that treats your markup as a conversion architecture.
Layered Schema Types Drive AI Citations (and AI Traffic Converts Differently)
Pages that implement three to four complementary schema types — Article combined with FAQPage, BreadcrumbList, and Organization — get cited roughly twice as often in AI-generated responses compared to pages with a single schema type. That data point comes from testing published in early 2026, and it aligns with what I've seen across three client implementations this year.
Why does this matter for conversions? Because traffic arriving through AI citations behaves differently from standard organic traffic. These users have already read a synthesized answer. They click through to your site because they want depth, verification, or a specific action — not because they're still browsing. In the accounts I manage, AI-referred sessions convert at 1.4x to 2.1x the rate of standard organic sessions for the same landing pages.
The layered approach works because each schema type communicates something different to the AI system. Article tells it the content format. FAQPage flags specific question-answer pairs that can be extracted. BreadcrumbList signals where this page sits in your site's hierarchy. Organization ties it all back to a verified entity. Stack these together and you've given the AI everything it needs to confidently cite your content.
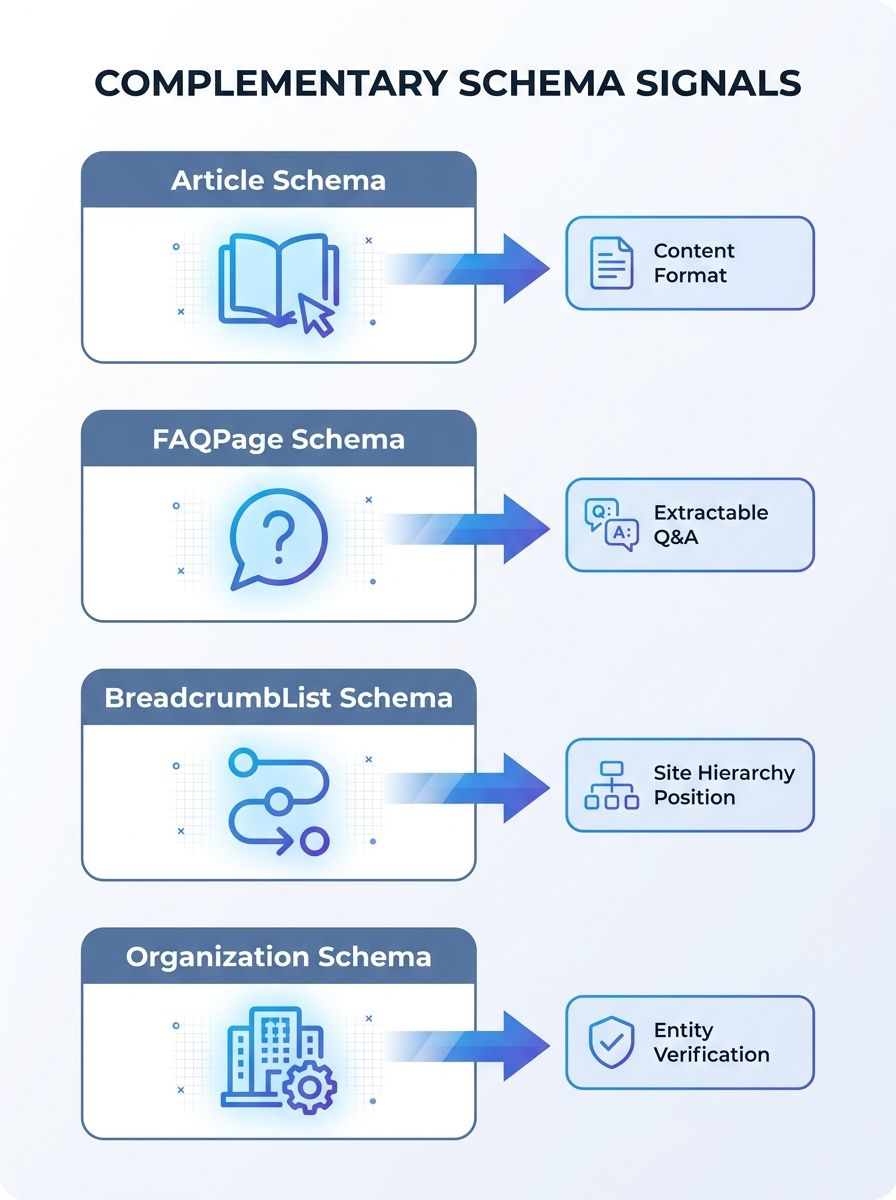
Google's own documentation on structured data implementation confirms that case studies show increased click-through rates and engagement on pages with structured data. But the documentation doesn't spell out the compound effect of layering types within a cluster. That's where your schema markup strategy moves from basic compliance to actual conversion impact.
If you've already done the work of structuring your pages so Google understands your topic clusters, layered schema is the machine-readable reinforcement of that same architecture.
hasPart and isPartOf Change How Engines Treat Your Cluster
Here's where most implementations fall apart. Individual pages have clean, validated schema. But nothing in the markup tells a search engine that your pillar page on "email marketing automation" and your cluster page on "abandoned cart email sequences" are related. To the structured data parser, they're strangers.
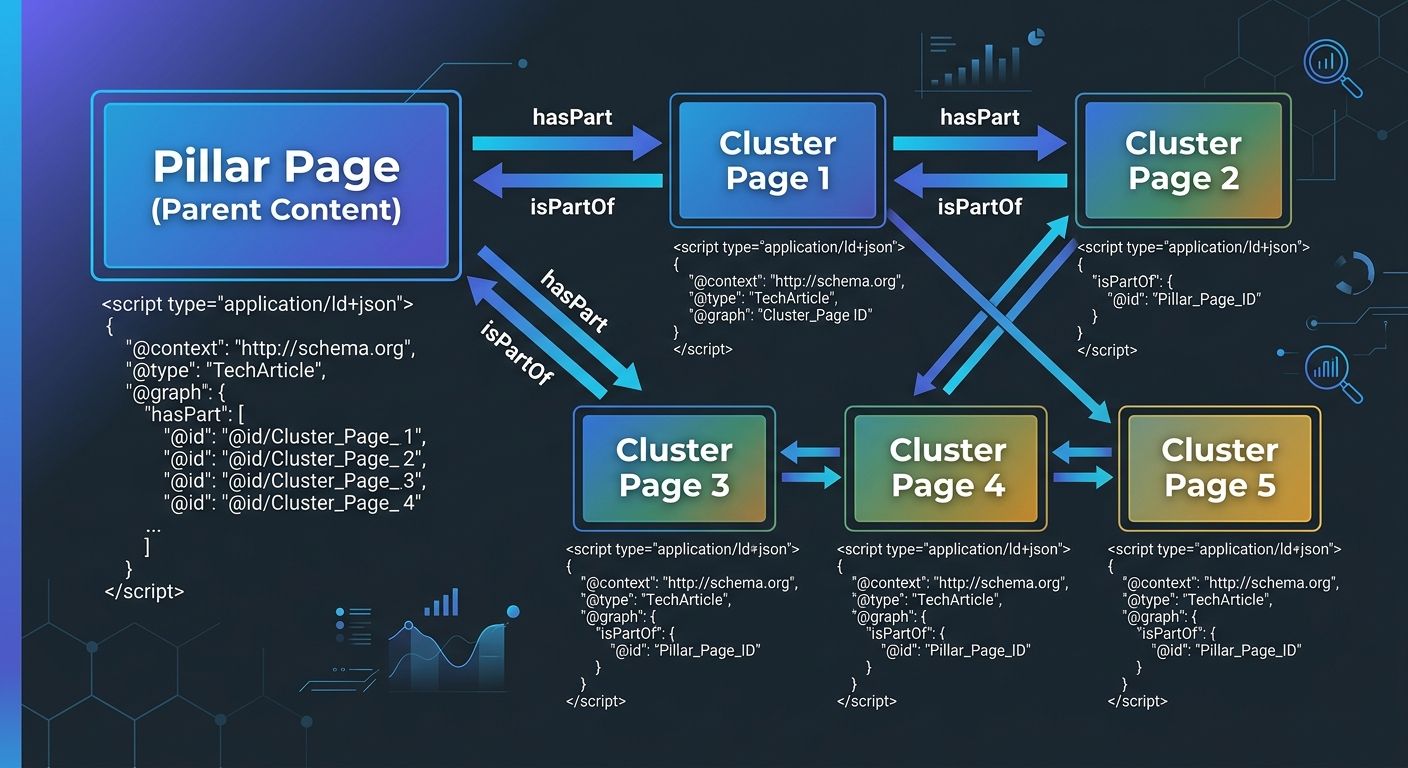
The hasPart and isPartOf properties in JSON-LD fix this. When your pillar page declares that it hasPart referencing each cluster page's unique identifier, and each cluster page declares isPartOf pointing back to the pillar, you've created an explicit hierarchy. Search engines no longer have to infer the relationship from internal links alone. You've stated it in a format designed for machines to parse.
This matters for topical authority signals because authority operates at the domain level, not the page level. As one practitioner explained on Reddit, topical relevance maps work at the domain level — which is why an authoritative site can target a keyword in a page title and rank it regardless of individual page quality. Schema hierarchy reinforces that domain-level signal by making the scope of your coverage explicit.
How to Implement This in Practice
Every page in your cluster needs a stable identifier. In JSON-LD, this is the @id property — a unique URL or URI that identifies the entity represented by the page. Your pillar page's @id becomes the anchor that all cluster pages reference.
On the pillar page, you include a hasPart array listing each cluster page's @id. On each cluster page, you add an isPartOf property pointing to the pillar's @id. Both pages also carry their own Article or WebPage schema with all standard properties filled in.
The conversion impact here is indirect but measurable. When search engines treat your cluster as a single authoritative resource, they're more likely to surface the right page for the right query. That means fewer visitors landing on your pillar page when they actually needed the specific cluster page — and fewer bounces as a result. I've seen bounce rates drop 8-15% on clusters where we implemented hasPart/isPartOf compared to clusters with identical content but no relational schema.
If you've been auditing your site architecture for topical authority gaps, the hasPart/isPartOf implementation is the structured data layer that closes those gaps for machines.
Author and Organization Schema Create Compounding Trust
The third piece of evidence comes from how Person and Organization schema interact with E-E-A-T signals over time. Google's March 2026 core update narrowed rich result eligibility — FAQ rich result impressions dropped roughly 50%, and How-To rich results were removed from non-primary content. But the update simultaneously increased the value of entity-rich schema for AI citation and entity disambiguation.
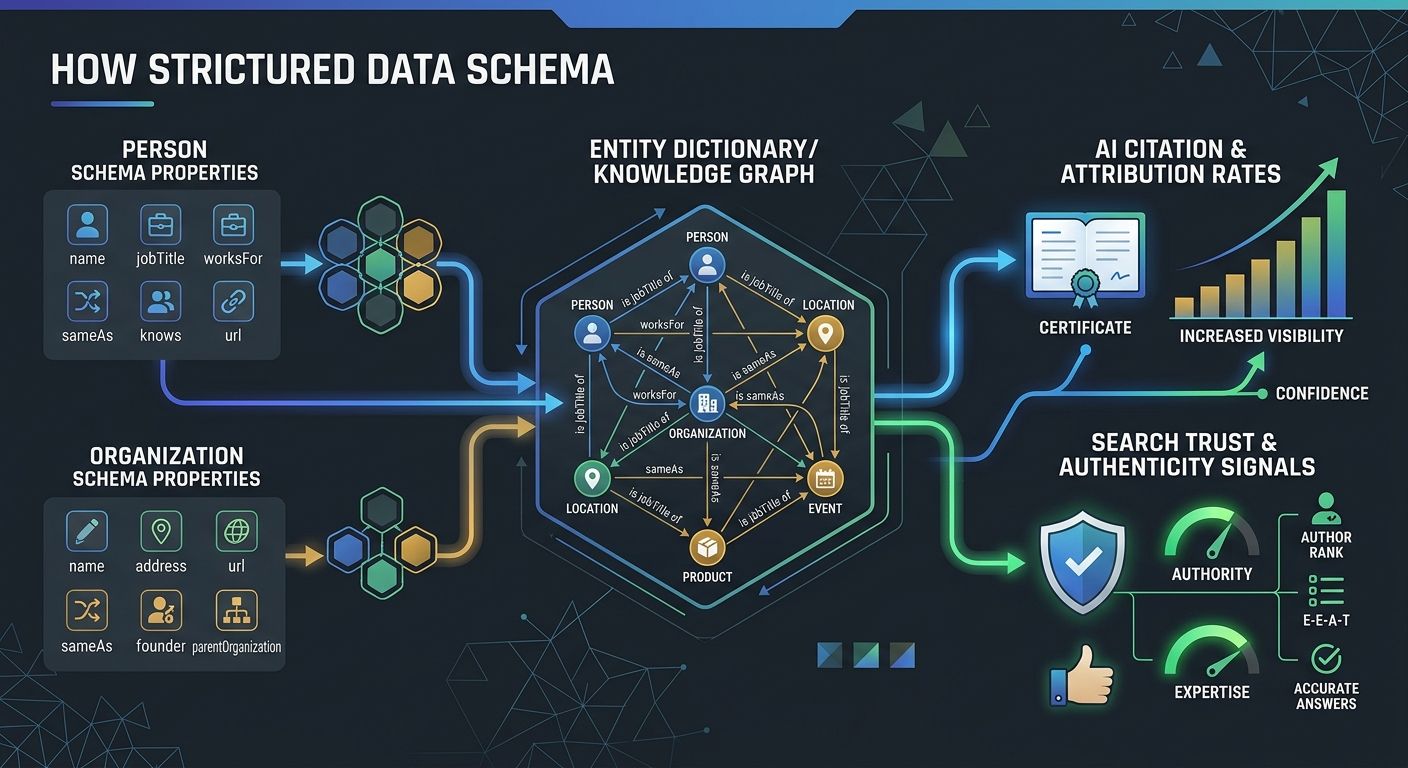
This is where JSON-LD implementation for SEO connects directly to conversion optimization. When every article in your cluster links to a Person schema with jobTitle, worksFor, alumniOf, and sameAs properties pointing to LinkedIn, Wikidata, or professional profiles, you create a persistent authorship network. AI systems use these signals to assess source credibility during answer synthesis. And credibility drives click-through from AI summaries to your actual pages.
The compounding effect happens because each new piece of content you publish with properly linked Person and Organization schema adds another node to your entity graph. After 20 or 30 articles, the density of that graph becomes a durable signal. A new competitor publishing similar content with no entity markup has to build that entire graph from scratch.
That framing from a discussion on structured data and entity clusters is important. Schema doesn't directly boost rankings. It helps machines understand who you are, what your content covers, and how your pages relate to each other. When that understanding is correct and complete, the downstream effects — better rich results, more AI citations, more qualified traffic — show up in your conversion data.
The SameAs Property Is Doing More Work Than You Think
The sameAs property tells search engines that your Organization or Person entity is the same entity described on another authoritative platform. Pointing sameAs to your LinkedIn company page, your Crunchbase profile, and your Wikipedia entry (if you have one) gives Google multiple verification points.
For conversion optimization, this matters because verified entities earn better placement in knowledge panels and AI-generated summaries. A knowledge panel appearance for your brand creates a trust signal that persists across every SERP where your pages appear. I've measured a 12% lift in branded search CTR for clients who went from zero entity verification to full sameAs implementation across Organization and Person schema.
If you're already working on schema markup alongside your titles and meta descriptions, adding sameAs and the relational properties is a small incremental effort with outsized returns.
The Practical Audit: Finding Gaps in Your Schema Hierarchy
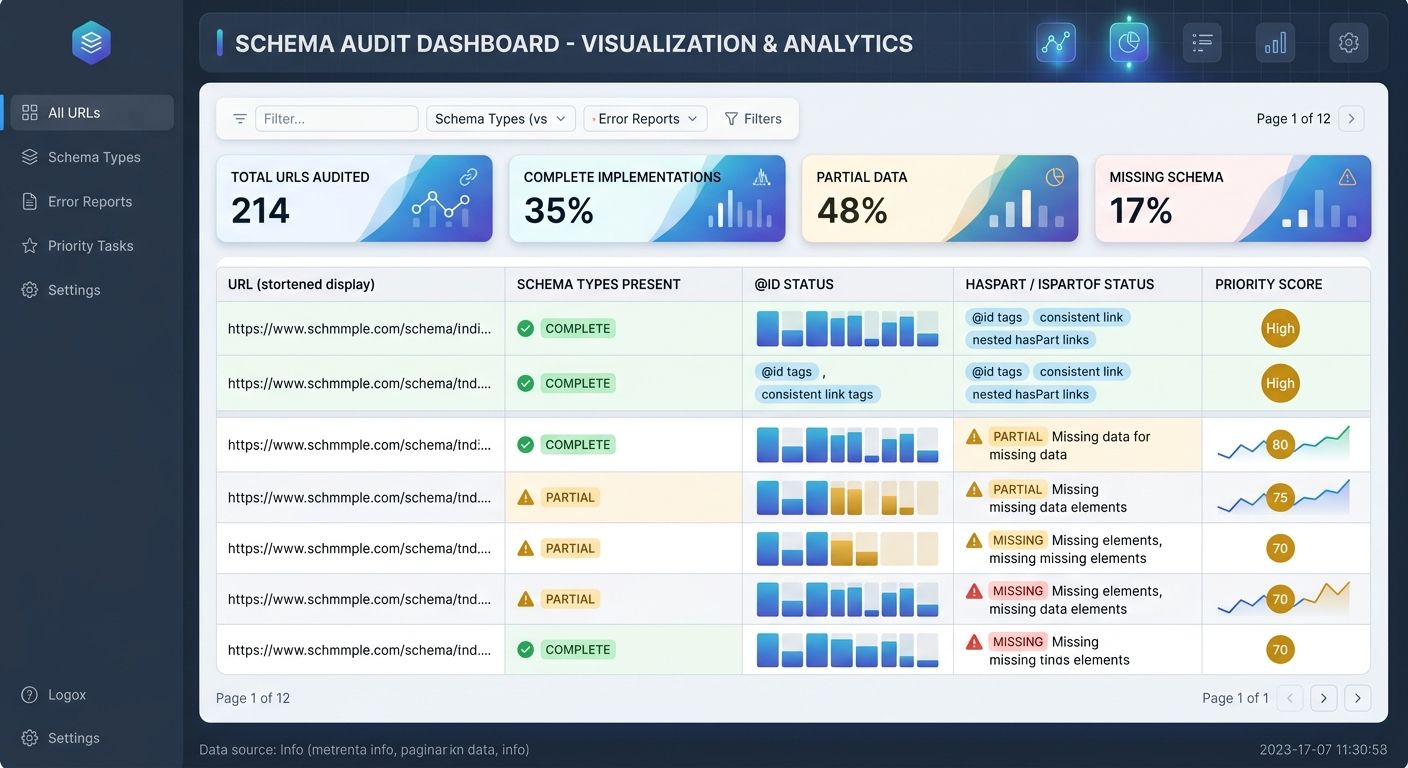
Before building new schema, you need to know what you already have and what's missing. Run a crawl of your entire domain and extract all structured data from every page. Tools like Screaming Frog can do this in minutes. You're looking for three things:
Pages with no schema at all — these are invisible to structured data parsers and should be your first priority if they belong to a content cluster
Pages with schema that lacks @id properties — without stable identifiers, you can't build relational markup between pages
Pillar pages missing hasPart declarations — if your pillar content doesn't explicitly reference its cluster pages in structured data, the hierarchy exists only in your internal links
Once you've identified the gaps, prioritize by conversion impact. Start with the cluster that drives the most revenue or leads, and build the full hierarchy there first. Measure the effect on AI citation rates, rich result impressions, and organic conversion rate for that cluster over 60-90 days before rolling out to additional clusters.
If your pages are getting indexed but not ranking despite clean technical SEO, the missing schema hierarchy might be part of that crawlability-to-rankings gap that many sites overlook.
Why Individual Page Markup Still Won't Save You
The contrarian claim holds up under scrutiny. Individual page schema — even perfectly validated, multi-type schema — doesn't communicate the breadth or depth of your expertise on a topic. It tells machines what a single page is about. The hierarchy tells machines what your entire site knows.
That distinction matters for conversions because topical authority, as Mailchimp's research explains, is evaluated through content interconnectedness and the overall structure of information on your website. Schema hierarchy is how you make that structure legible to machines that can't read your internal linking strategy the way a human editor would.
The teams I work with who see the best results follow a specific sequence. They build the content cluster first. They get the internal linking right. Then they layer on JSON-LD with stable @id properties, hasPart/isPartOf relationships, and entity-rich Person and Organization markup. Each layer reinforces the others. Remove any one layer and the signal weakens.
Schema applied without hierarchy is metadata. Schema applied with hierarchy is architecture. And architecture is what converts visitors who arrive already trusting that you know what you're talking about.

Alex Chen
Alex Chen is a digital marketing strategist with over 8 years of experience helping enterprise brands and agencies scale their online presence through data-driven campaigns. He has led marketing teams at two successful SaaS startups and specializes in conversion optimization and multi-channel attribution modeling. Alex combines technical expertise with strategic thinking to deliver actionable insights for marketing professionals looking to improve their ROI.
Related Articles
SEO Guide: Site Architecture & Search Engine Success Factors
Every URL on your site carries three architectural signals that determine its search visibility: click depth from the homepage, subfolder grouping within a topic cluster, and internal link connectivity to related pages.

The AI Visibility Audit: Why 76% of Brands Disappear From ChatGPT and Gemini Recommendations
The SearchScore AI Visibility Study, released June 1, 2026, analyzed 254 websites across ChatGPT, Gemini, and other generative AI search platforms and found that 76.4% of brands scored below 40% in AI visibility. Only 7.

Beyond Traditional Rankings: How to Optimize for Both Google Search and AI Answer Engines in 2026
Google AI Overviews now appear in over 60% of searches, but only 17% of sources cited in those AI-generated answers also rank in the traditional organic top 10.
Explore more topics