AI Scrapers and Your SEO: How Content Licensing Threats Are Reshaping Keyword Strategy in 2026
Akamai reported a 300% surge in AI bot traffic this year, and publishers took the hardest hit. That number alone should change how you think about your keyword strategy.
AI Scrapers and Your SEO: How Content Licensing Threats Are Reshaping Keyword Strategy in 2026
Akamai reported a 300% surge in AI bot traffic this year, and publishers took the hardest hit. That number alone should change how you think about your keyword strategy. But here's what really caught my attention this week: a Digiday investigation published April 9 revealed that a growing network of third-party web scrapers is now fueling an entire underground market where your content gets harvested, repackaged, and sold to AI companies without your consent. Your carefully optimized articles aren't just ranking in search results anymore. They're being strip-mined to train the very systems that are replacing those search results.
The AI content scraping SEO impact is no longer theoretical. It's measurable, it's accelerating, and it demands a fundamentally different approach to keyword strategy.
The March 2026 Core Update Changed the Rules
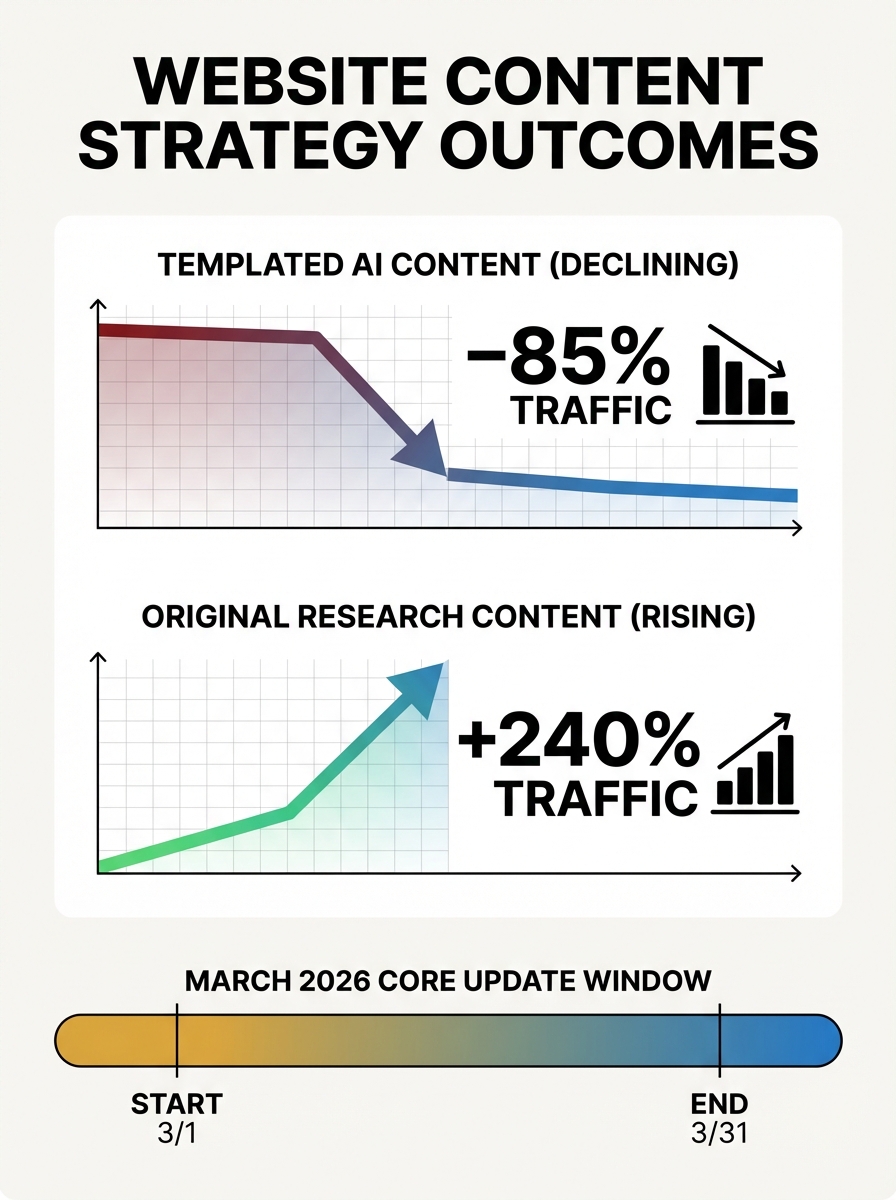
Google's March 2026 core update rolled out between March 27 and April 8, and it landed with real force. This was Google's first broad core update of the year, and the signal was unmistakable: content that provides "information gain" now has a clear ranking advantage over content that rephrases what already exists.
Sites relying on scaled or templated AI content saw traffic declines of up to 71%. Meanwhile, sites publishing original research or proprietary data saw visibility increases of roughly 22%. The spam update that preceded it, completed in under 20 hours on March 24-25, showed Google's systems are getting frighteningly fast at identifying and demoting low-quality AI-generated content.
If you've been tracking the broader impact of the core update and AI bot traffic on competitive rankings, you already know the landscape shifted dramatically. But the scraping angle adds a dimension most SEO teams aren't prepared for.
Third-Party Scrapers Are the New Threat Vector
The scrapers aren't coming from the AI companies themselves anymore. A shadow ecosystem of third-party operators is crawling publisher sites, packaging that content, and licensing it to AI training pipelines. As Akamai's report put it: "These bots are not just a security nuisance, they represent a profound business challenge that threatens the sustainability of quality journalism."
The BBC, The New York Times, and The Guardian are all actively blocking AI crawlers as of early April 2026. But blocking known bots is just the start. These third-party scrapers are harder to identify because they don't announce themselves the way Googlebot or GPTBot do.
Content licensing threats in 2026 are no longer confined to major publishers. If you're running a B2B content operation with detailed guides, benchmarks, or industry data, your content is valuable training material. And someone may already be harvesting it.
This is where your analytics implementation becomes critical. If you can't accurately distinguish bot traffic from human traffic, you're flying blind on both your SEO performance data and your exposure to content scraping.
Why Your Keyword Strategy Needs to Change Now
The traditional approach to keyword strategy goes something like this: find high-volume terms, create content that matches search intent, optimize for rankings. That playbook isn't dead, but it's dangerously incomplete.
When AI systems scrape your content and use it to generate answers directly, you lose the click. Zero-click searches powered by AI overviews mean your perfectly optimized article might inform the answer without ever sending you a visitor. The AI content scraping SEO impact hits you twice: once when your content trains the model, and again when that model's response replaces your organic listing.
So what do you optimize for instead?
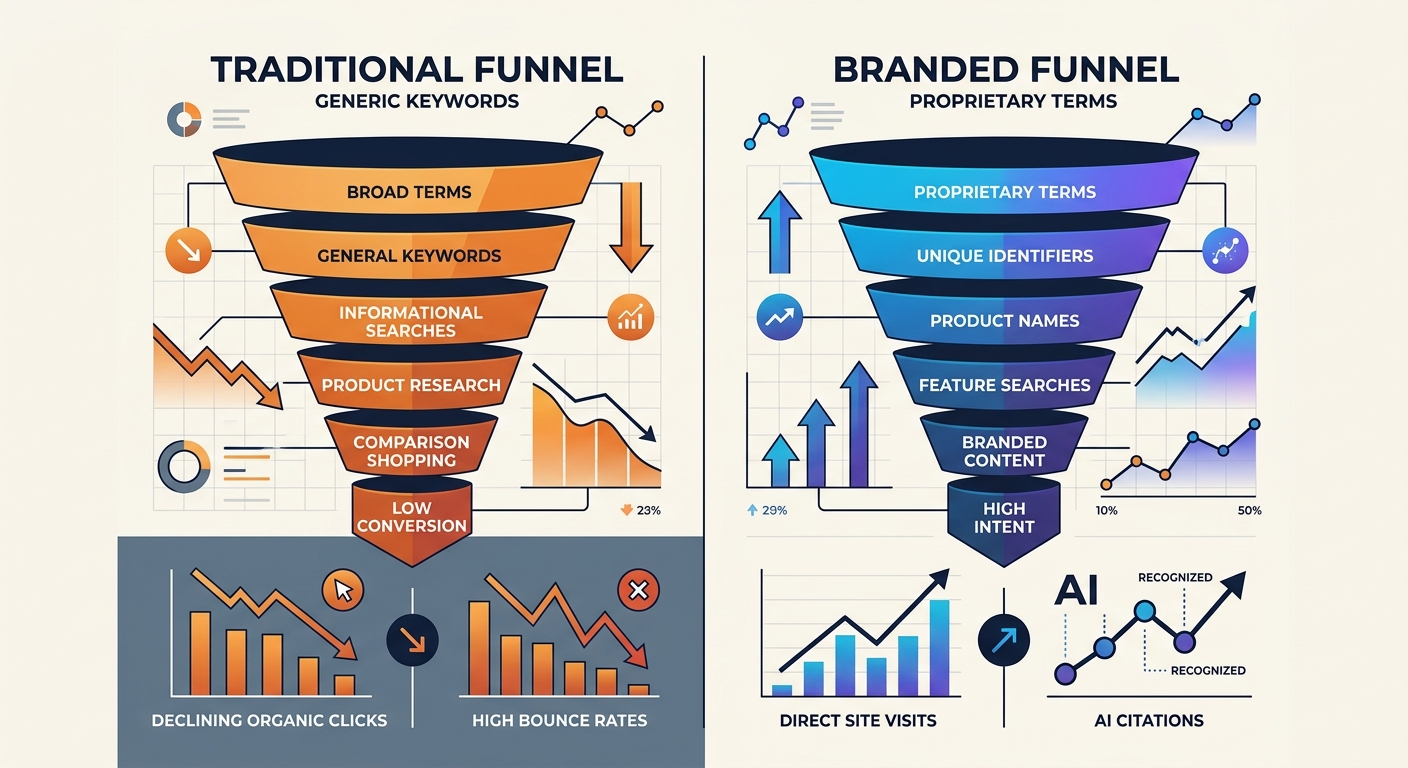
Build a Branded Search Strategy
The keywords that AI can't steal from you are the ones with your name attached. Branded search strategy is becoming the most defensible category in SEO, and teams that invested early are seeing it pay off.
When someone searches for your brand name, your proprietary framework, or your coined methodology, AI overviews still point back to you. The model knows where that concept originated. Your branded terms create a direct connection between the searcher and your site that intermediary AI responses can't easily intercept.
This means your keyword research should now include deliberate creation of branded terms:
Name your frameworks. If you have a process for auditing content performance, give it a name. "The Content Velocity Audit" is searchable and attributable. "How to audit your content" is not.
Coin terminology for your original research. When you publish benchmark data, attach a branded label to it.
Build topic authority around your branded concepts so that AI systems associate those terms with your domain.
The shift from generic informational keywords to branded conceptual keywords isn't about abandoning search volume. It's about building terms that carry attribution even when scraped.
The Proprietary Content Moat Is Real
I've been skeptical of the phrase "content moat" for years because most companies used it to describe a pile of mediocre blog posts. That's not a moat. That's a landfill.
But a proprietary content moat built on original data, unique research, and first-party insights is genuinely defensible against AI scraping. When Google's systems reward "information gain," they're specifically looking for content that adds something new to the conversation. If your content is just a synthesis of what already exists, an AI model can replicate it trivially. If your content contains data that only you have, the model needs to cite you.
This aligns with what Search Engine Land reported about evolving bot strategies: businesses with existing bot management approaches will need to evolve them significantly throughout 2026. The technical side of bot management is important, but the content side matters even more.
Practical ways to build your content moat:
Run original surveys. Even small sample sizes (n=200+) create citable data points that AI models attribute to your brand.
Publish proprietary benchmarks. If you have access to platform data, anonymize and aggregate it into industry benchmarks.
Create tools and calculators. Interactive content can't be scraped the same way text can. A calculator that requires inputs generates unique outputs.
Document case studies with specific numbers. The more specific your data, the harder it is to genericize. When you're building content hubs around pillar page strategy, anchor each hub to proprietary data rather than recycled industry talking points.
AI Search Visibility Requires a Different Optimization Model
Getting your content to rank in traditional search results and getting it cited by AI systems are increasingly two different problems. AI search visibility depends on factors that don't map neatly onto traditional ranking signals.
As the BBC reported this week, businesses are scrambling to get noticed by AI search, restructuring how they present information so AI systems can parse and recommend it. Pages structured with clear headings, direct answers, and verifiable expertise are more likely to be cited in AI overviews and LLM-generated responses.
This means your content needs to serve two masters simultaneously:
For traditional search: You still need strong E-E-A-T signals, technical performance, and topical authority. If your search rankings have dropped post-update, the traditional diagnostics still apply.
For AI recommendations: You need structured assertions. Clear, quotable statements of fact. Named entities. Specific data points with dates. AI systems prefer content they can extract a clean, attributable answer from.
The overlap between these two is growing, but the AI optimization layer adds specific requirements. You should be targeting "People Also Ask" questions with direct, authoritative responses in your content. Structure your key insights as standalone statements that make sense even when extracted from context.
If you're rethinking your overall approach to optimizing for AI recommendation engines alongside traditional search, the core principle is this: write for citation, not just for clicks.
Defending Against the Scraper Economy
The convergence of the March 2026 core update, the third-party scraper market, and the ongoing shift toward AI-mediated search results means you can't wait on this. Here's what I'd prioritize:

Immediate (this week):
Audit your server logs for unusual bot activity. Look beyond named AI crawlers for third-party scraper patterns.
Review your robots.txt and consider implementing more aggressive bot management, including rate limiting and tarpitting for suspicious crawlers.
Identify your top 20 organic pages by traffic and assess how many could be replicated by an AI model without citing you.
Short-term (this month):
Develop a branded keyword strategy. Map every proprietary framework, methodology, or data set you own and ensure each has a searchable, named identity.
Start one original research project that will produce citable data within 60 days.
Restructure your highest-value content to include clear, extractable statements optimized for AI citation.
Ongoing:
Monitor the balance between organic SEO investment and paid approaches as AI scraping continues to erode organic traffic for informational queries.
Track your content's appearance in AI-generated answers. Tools are still catching up here, but manual spot-checking for your branded terms in ChatGPT, Perplexity, and Google AI Overviews will give you directional data.
Build relationships with AI companies directly. Licensing partnerships are emerging where publishers grant controlled access in exchange for attribution and compensation.
The content licensing threats of 2026 aren't going away. If anything, the Digiday report this week suggests the scraping ecosystem is becoming more sophisticated, not less. Your best defense isn't purely technical. It's strategic: create content that's so original, so tied to your brand, and so rich with proprietary data that AI systems have to attribute it to you. That's the keyword strategy that survives what's coming next.

Sarah Chen
SEO strategist and web analytics expert with over 10 years of experience helping businesses improve their organic search visibility. Sarah covers keyword tracking, site audits, and data-driven growth strategies.
Frequently Asked Questions
- How much has AI bot traffic increased in 2026?
- Akamai reported a 300% surge in AI bot traffic this year, with publishers taking the hardest hit from this increase.
- What were the results of Google's March 2026 core update?
- Google's March 2026 core update, rolled out between March 27 and April 8, prioritized content with "information gain" over rephrased content. Sites relying on scaled or templated AI content saw traffic declines up to 71%, while sites publishing original research saw visibility increases of roughly 22%.
- How can I protect my content from AI scrapers?
- Audit your server logs for unusual bot activity and unfamiliar user agents beyond named AI crawlers, review your robots.txt, implement bot management strategies like rate limiting, and build a proprietary content moat using original research and data that AI systems must attribute to you.
- What is a branded keyword strategy and why does it matter?
- Branded keyword strategy focuses on searchable terms tied to your name, frameworks, and coined methodologies that AI systems can't easily intercept because they know where the concept originated. When someone searches for your brand or proprietary framework, AI overviews still point back to your site.
- What content types are hardest for AI to scrape?
- Interactive content like tools and calculators can't be scraped the same way text can, as they generate unique outputs based on user inputs. Original surveys, proprietary benchmarks, and case studies with specific numbers are also harder to genericize.
- How should I optimize content for AI search visibility?
- Structure content with clear headings, direct answers, named entities, and specific data points with dates. Front-load key claims in the first two sentences of each section, use declarative statements over hedged language, and target "People Also Ask" questions with authoritative responses that AI systems can extract and attribute.
- What are third-party web scrapers and why are they a threat?
- Third-party web scrapers are operators that crawl publisher sites, package content, and license it to AI training pipelines without publisher consent. They're harder to identify than official AI bots because they don't announce themselves like Googlebot or GPTBot, representing a sophisticated new threat vector to content licensing.
Explore more topics