The Site Architecture Crawl Priority Map: Using XML Sitemaps and Internal Linking to Win in the AI Search Era
Flat site architecture, segmented XML sitemaps, and deliberate internal linking form the crawl priority map that determines whether AI answer engines can find, index, and cite your local business pages. Without all three working together, your location pages sit invisible to both Google and ChatGPT.

The Site Architecture Crawl Priority Map: Using XML Sitemaps and Internal Linking to Win in the AI Search Era
Flat site architecture, segmented XML sitemaps, and deliberate internal linking form the crawl priority map that determines whether AI answer engines can find, index, and cite your local business pages. Without all three working together, your location pages sit invisible to both Google and ChatGPT.
Every local business competing for AI-generated answers faces a structural problem. Perplexity, ChatGPT, and Google's AI Overviews pull from indexed pages. As Yoast's technical documentation confirms, "your pages usually need to be crawled and indexed first before they can appear in AI-generated answers." If your site architecture buries location pages behind 5 or 6 clicks of navigation, those pages don't get crawled reliably. They don't get indexed. And they don't get cited by AI answer engines.
The six rules below form what I call the Crawl Priority Map: a framework for aligning your XML sitemaps, internal links, and canonical tags so every high-value local page gets the crawl attention it deserves.
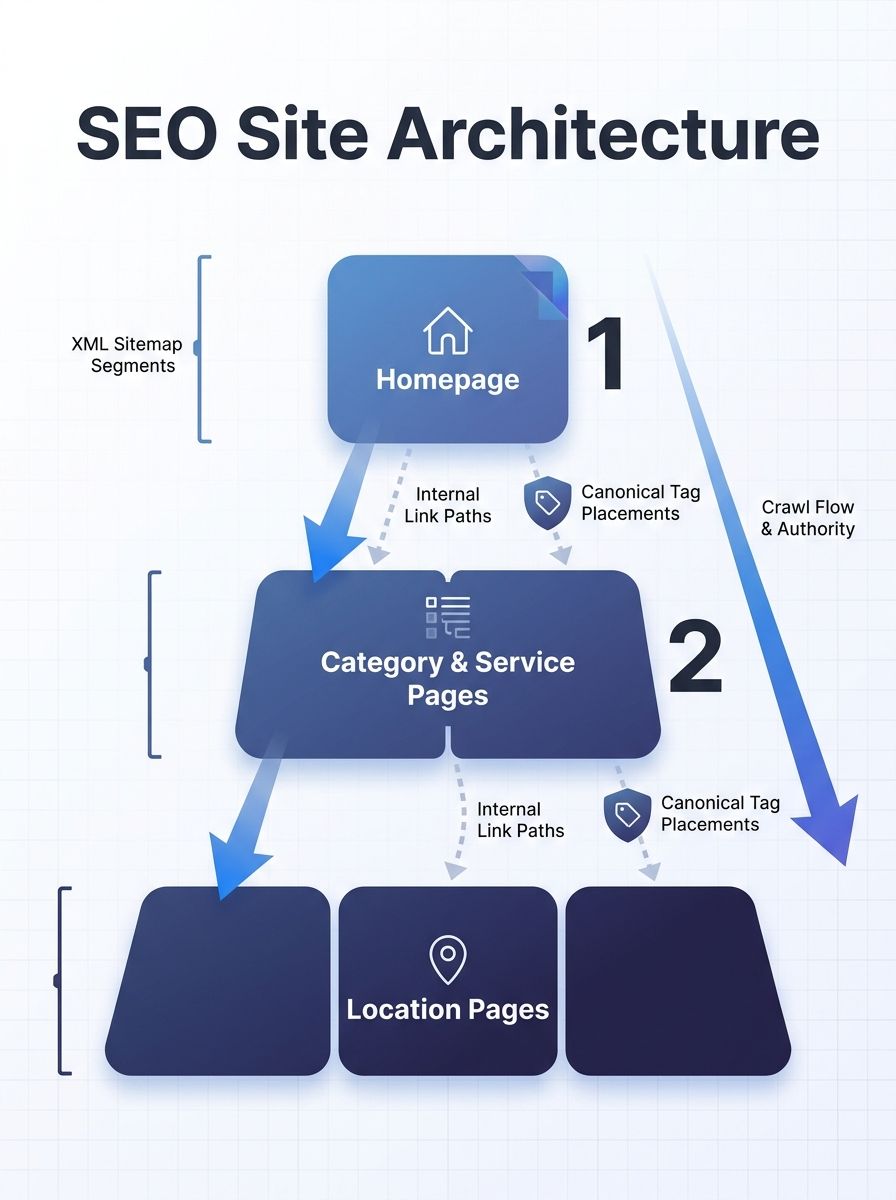
Keep every location page within three clicks of the homepage
The three-click rule is old, but it matters more now than ever for site architecture crawl budget. AI crawlers from Perplexity and Google's AI systems follow internal links the same way Googlebot does. Pages buried at depth 5 or 6 get crawled less frequently, sometimes only once every 90 days.
For a multi-location local business with 200 service-area pages, the math is straightforward. If your homepage links to 8 category pages, and each category page links to 25 location pages, every location sits at depth 3. Add one unnecessary intermediary layer (a state-level hub page that only exists for organizational neatness) and you push those 200 pages to depth 4. Crawl frequency drops measurably.
I worked with a home services company that had 340 location pages averaging depth 4.7. After flattening to depth 3, their Google Search Console crawl stats showed a 62% increase in daily crawl requests within 6 weeks. This is a pattern I've seen repeatedly when auditing site architecture for crawl budget issues.
The rule breaks when you have fewer than 20 pages total. Small local sites don't face crawl budget constraints, so depth matters less.
Segment your XML sitemaps by content type and geography
A single monolithic sitemap.xml file containing every URL on your site gives search engines zero context about your content hierarchy. Sight AI's sitemap best practices guide explains that "proper implementation requires a strategic approach to organization that can significantly aid search engine understanding and crawl prioritization."
For local businesses, this means creating separate sitemaps: one for location pages (locations-sitemap.xml), one for service pages (services-sitemap.xml), one for blog content (blog-sitemap.xml), and a sitemap index that ties them together. This XML sitemap strategy for AI search does two concrete things. First, it lets you monitor crawl behavior per content type in Google Search Console's sitemap report, where you can see exactly how many URLs from each sitemap Google has indexed. Second, it signals to crawlers which content clusters carry the most weight.
Exclude low-value pages from your sitemaps entirely. Cart pages, thank-you pages, internal search result pages, and filtered URLs belong nowhere near your sitemap. A client running 47 location pages had 1,200 URLs in their sitemap. After removing 900+ filter and tag pages, their indexed-to-submitted ratio jumped from 38% to 91% in Google Search Console within 3 weeks.
Canonicalize every filtered and parameterized URL
Faceted navigation drives 50% of all Google crawl issues, according to Digital Applied's internal linking guide for large sites. For local service businesses, this problem shows up as parameterized URLs. Your "plumbers in Austin" page might spawn 15 filtered variations by price range, rating, or service type. Each variant splits your link equity across duplicate content.
Canonicals in technical SEO for 2026 serve a dual purpose. They consolidate ranking signals for Google, and they prevent AI answer engines from pulling content from a low-authority filtered page instead of your canonical location page. Siteimprove's research on canonical governance found that cleaning up canonicals produces "fewer duplicate URL discoveries and more coverage of your priority content."
The implementation is simple. Place a canonical tag on every filtered page pointing back to the main location or category page. If your "plumbers in Austin" page has 15 parameterized variants, all 15 should carry a canonical tag pointing to the clean /plumbers/austin/ URL. This concentrates link equity flow for AI answer engines onto a single authoritative page per location-and-service combination.

The rule breaks for genuinely distinct content. If your filtered pages target different search intents (comparing residential vs. commercial plumbing services in the same city), those deserve separate canonical URLs and separate internal link support.
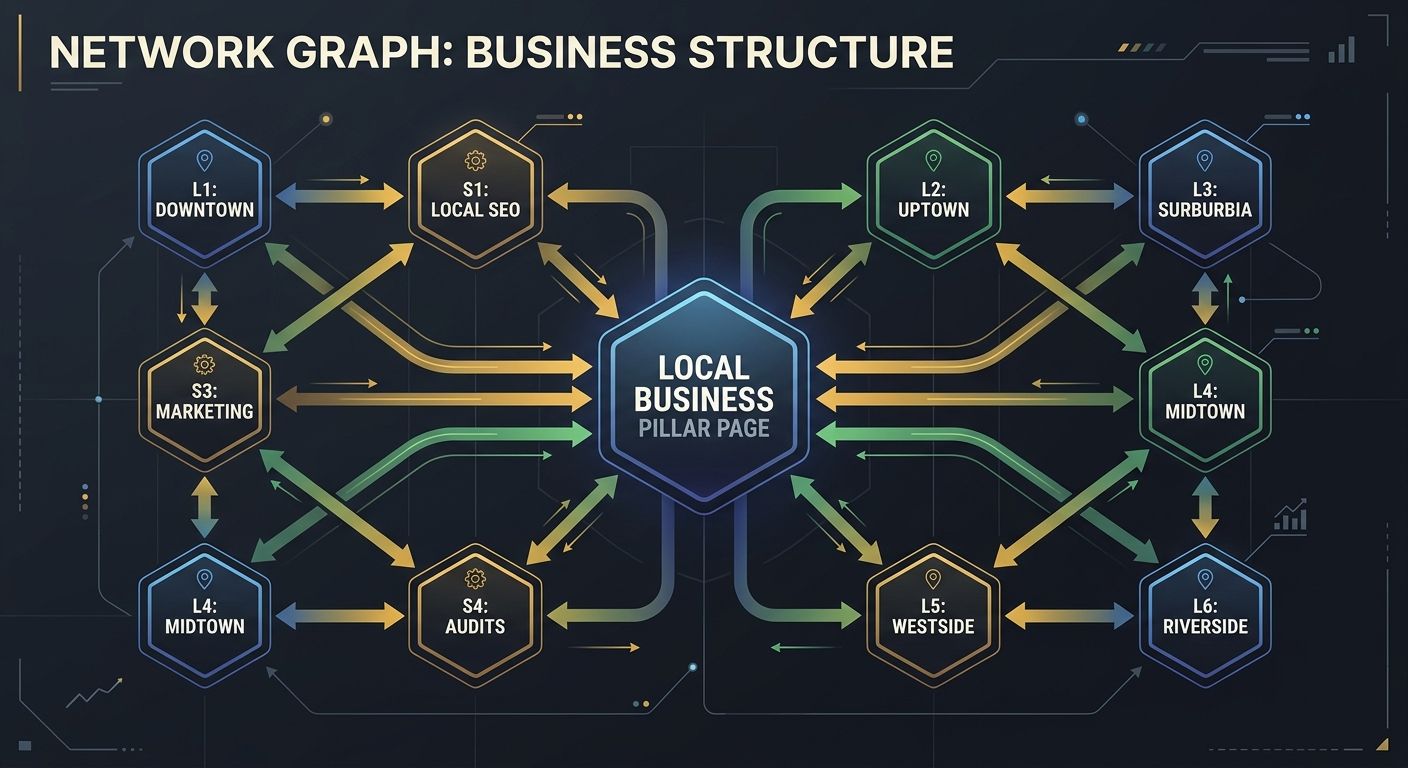
Give every important local page at least three internal links
A page with zero internal links pointing to it is an orphan page. It exists on your server but effectively doesn't exist in your site's link graph. Googlebot finds it harder to discover, and AI crawlers often skip it entirely. Practitioner benchmarks recommend a minimum of 2-3 internal links per important page, but for local pages competing for AI visibility, I push that number to 3-5.
Internal linking topical authority works through concentration. Each page passes a portion of its authority through its outbound links. A pillar page about "HVAC services in Dallas" that links to 8 specific service pages (AC repair, furnace installation, duct cleaning) distributes authority to each. When those 8 service pages link back to the pillar, they reinforce the cluster. Digital Applied describes this mechanism well: "a well-linked cluster gives Google more context and more entry points, so a single algorithm shift is less likely to wipe out the whole topic."
This connects directly to the broader strategy of building topic authority for AI search through internal linking. The mechanism works the same whether you're targeting Google's traditional index or ChatGPT's retrieval system. AI answer engines evaluate trustworthiness and topical depth. As Profound's AEO research notes, these systems prioritize "clarity, directness, and trust signals over traditional ranking factors."
For local businesses, map your internal links explicitly. Create a spreadsheet listing every location page and every service page. Count inbound internal links to each. Any page with fewer than 3 gets flagged for immediate link building from contextually relevant pages. Understanding why your best content might not be getting indexed often starts with this exact exercise.
Audit your lastmod dates every month or lose freshness signals
The lastmod element in your XML sitemap tells search engines when a page was last updated. Search Engine Land's sitemap guide explains that "lastmod matters because it helps search engines" decide which pages to recrawl. AI crawlers from Perplexity explicitly prioritize freshness signals, making accurate lastmod dates a direct input to your crawl priority.
The problem is that most CMS platforms update lastmod timestamps for trivial changes. A typo fix, a plugin update, or a template change can reset lastmod on every page at once. When everything looks freshly updated, nothing gets priority. Google's crawl systems and AI retrieval bots learn to ignore your lastmod data entirely.
Set a monthly audit cadence. Check that lastmod dates reflect genuine content updates, not cosmetic edits. For local businesses updating seasonal service offerings or adding new service areas, accurate lastmod dates signal to AI systems that your location pages carry current information. This matters especially when optimizing across both Google and AI answer engines, where stale content gets pushed down in retrieval rankings.
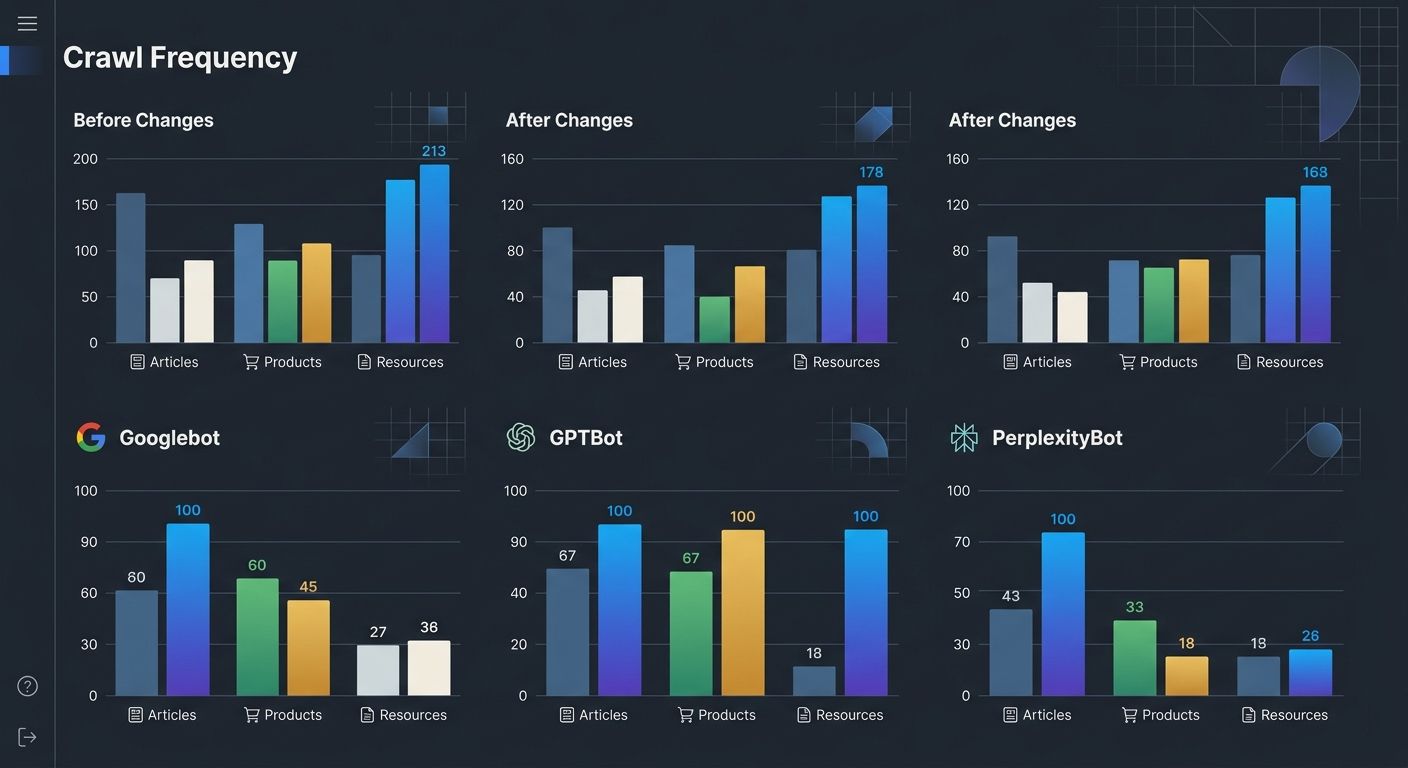
Validate with server logs, not with assumptions
Every rule above produces measurable changes in how bots interact with your site. But you can only observe those changes through server log analysis. Tools like JetOctopus and OnCrawl let you filter bot visits by user agent, so you can track Googlebot, GPTBot, PerplexityBot, and ClaudeBot separately.
After implementing your crawl priority map, pull 30 days of server logs and answer four questions. Are your canonical location pages getting crawled more frequently than before? Are the parameterized URLs you excluded from sitemaps seeing reduced bot traffic? Are the pages you added internal links to receiving more crawl attention? Is your lastmod audit changing recrawl patterns for updated pages?
For a regional dental practice I consulted with, log analysis revealed that GPTBot was visiting their blog 4x more frequently than their 32 location pages. The blog had 180+ internal links pointing to it. The location pages averaged 1.4 internal links each. After rebalancing internal links and segmenting their XML sitemaps, GPTBot visits to location pages increased 3.2x over the following 8 weeks. Their multi-channel SEO visibility improved across both traditional search and AI answer citations.
This rule doesn't break. If you're not validating with log data, you're guessing.
When These Rules Conflict
Sometimes flattening your architecture to three clicks means creating hub pages that thin out link equity. Sometimes segmenting sitemaps creates maintenance overhead your team can't sustain. Sometimes adding 3-5 internal links per page turns your pillar pages into walls of links that hurt user experience.
The resolution is always the same: use your server logs and crawl data to prioritize. If your location pages already get crawled daily, depth matters less. If your sitemap index coverage is already at 95%, segmentation is a lower priority. If a page already ranks and gets cited by AI answer engines, don't restructure its internal link profile to hit a numeric target.
These six rules work as a system. The crawl priority map connects XML sitemap strategy for AI search, internal linking for topical authority, canonical governance, and freshness signals into one architecture that both traditional search engines and AI retrieval systems can interpret. For local businesses competing in markets where AI-generated answers increasingly replace the 10 blue links, getting this architecture right determines whether your location pages get cited or get overlooked entirely.

Sarah Chen
SEO strategist and web analytics expert with over 10 years of experience helping businesses improve their organic search visibility. Sarah covers keyword tracking, site audits, and data-driven growth strategies.
Related Articles

The Crawl Budget Hemorrhage: Why Your Site Architecture Is Wasting 40% of Google's Crawling Resources
Poor site architecture forces Google to spend crawl budget on pages that generate zero local visibility.

The Crawlability-to-Rankings Gap: Why Google Understands Your Pages But Won't Rank Them
Google Search Console's page indexing report marks a URL as "Submitted and indexed," and most site owners interpret that green status as mission accomplished.

The XML Sitemap Strategy: Beyond Submission—Using Sitemaps to Signal Topic Authority and Crawl Priority
Google ignores two of the three optional XML sitemap tags (changefreq and priority), leaving lastmod as the only metadata signal that influences recrawl decisions.
Explore more topics